Have you ever wondered how you can duplicate posts and pages in WordPress? Sure, you can just copy and paste content from one place to another, but that is not so practical if you’re the source post or page is long and contains lots of blocks, images, headings, etc. Not only can that take time, but there is also a risk of making errors or missing something.
Mercifully, there are better ways of duplicating posts and pages in WordPress, as we will now show you.
Method 1: Duplicate Posts and Pages Using Gutenberg
If you use Gutenberg (the standard WordPress block editor), then duplicating pages and posts is relatively easy. Here’s how to do it:
Firstly, open the page or post which you wish to copy. Next, click the three dots (ellipsis) located at the top right of the edit screen. Scroll down the menu that pops up and click on “Copy All Blocks”:
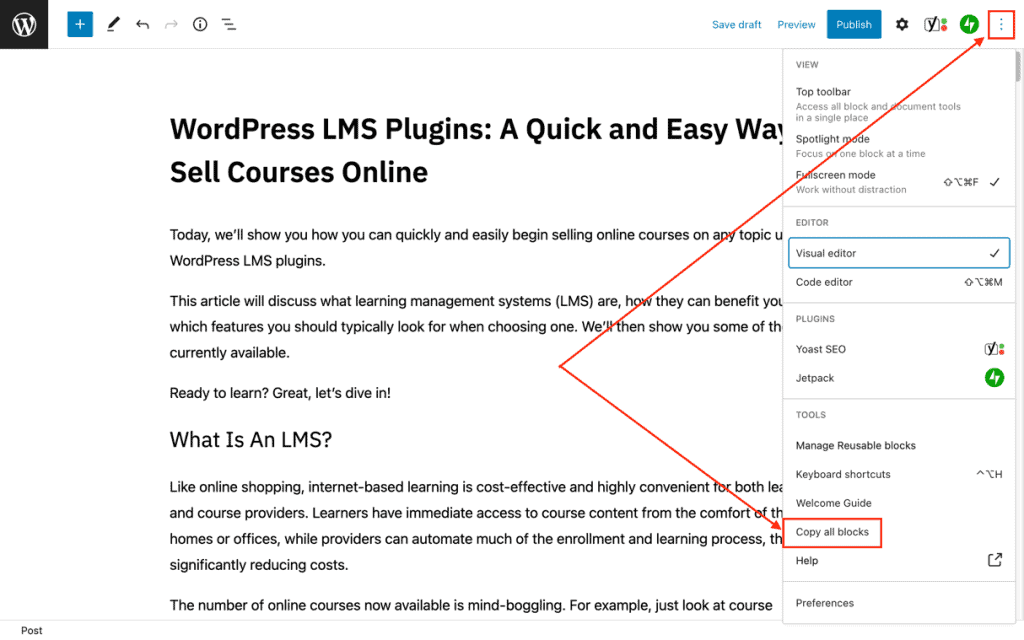
A message saying “All content copied” will appear. Please note, however, that the page title is not copied and will need to be entered manually.
Next, create a new page or post as appropriate and enter the title. In the next block, paste the copied content using the cmd + V shortcut or by right-clicking on your mouse and selecting ‘Paste.’ This inserts the entire contents (excluding the title) of the source page or post into your new post. All that is then left to do is make any changes required to this new page/post.
Please note you can also use this method to copy posts and pages from one site to another. Simply open the admin panels of both sites in separate tabs or windows, copy the content from the source page or post and paste it into a new page or post on the destination site.
Method 2: Duplicate Pages Using Elementor
If you use Elementor rather than Gutenberg, the process for duplicating posts and pages is a little more convoluted, as you will need to save the source page as a template.
Firstly, open the page you want to duplicate using Elementor. Next, go to the bottom left of the screen and click on the arrow next to the green ‘UPDATE’ button. Then, from the popup which appears, select ‘Save as Template’:
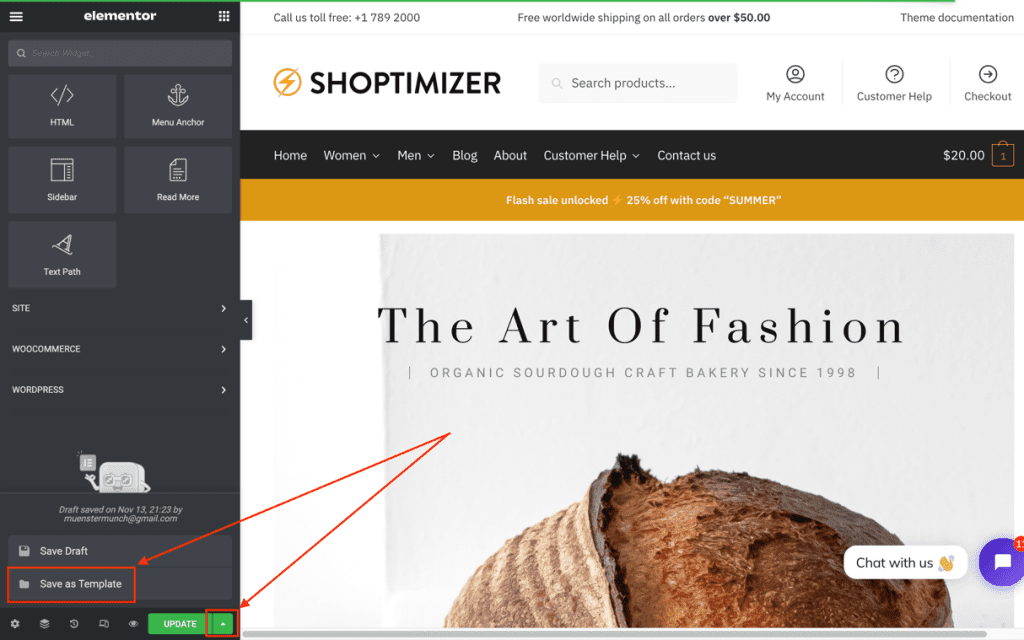
Give the template a memorable name and click the green ‘SAVE’ button:

The page will now be available in the Elementor template library for use as often as needed.
To duplicate the page, either create a new page or go to an existing page where you wish to insert the template. Then, click the folder icon to open the Elementor library:
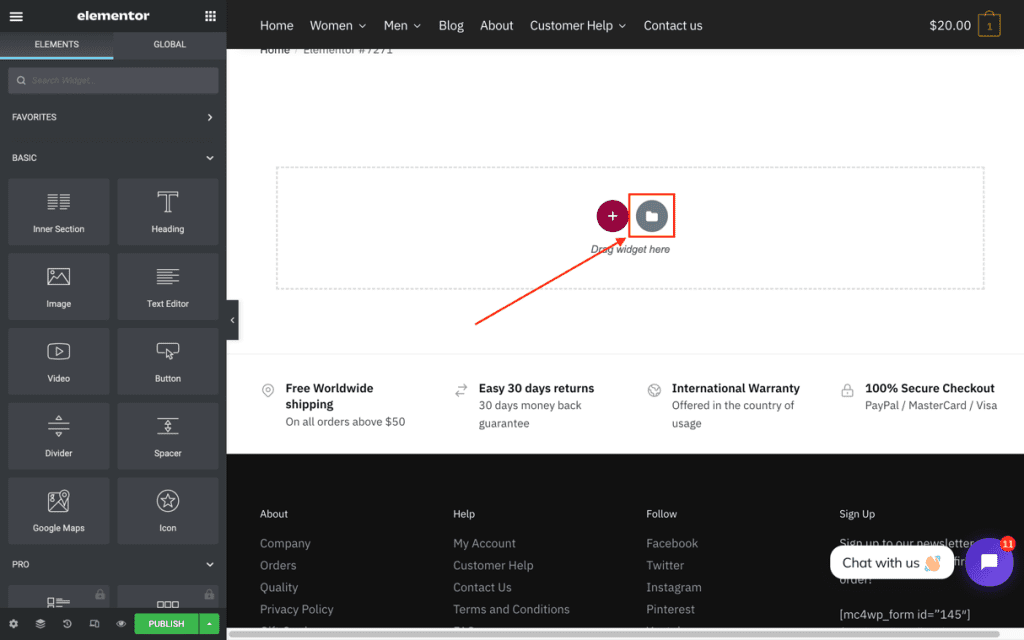
Click on the ‘My Templates’ tab in the library, find your new template in the list, and click ‘Insert’:
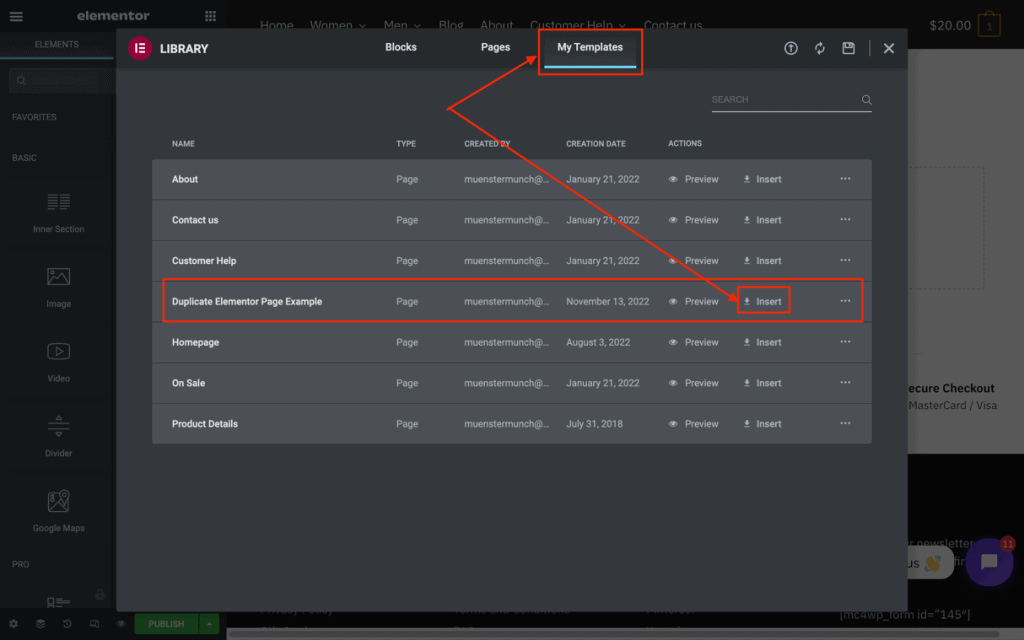
That’s it – you have now duplicated the page using Elementor!
Method 3: Duplicate Posts and Pages Using Plugins
Methods 1 and 2 above are fine if you only occasionally duplicate posts and pages in WordPress or if the content you are copying is relatively small. However, they are somewhat convoluted when creating multiple duplicates of longer content. In those cases, a plugin will likely be a better solution, as most will reduce the process to a single click.
Unfortunately, there are surprisingly few such plugins available. However, after much searching, here are five of the best we found:
Yoast Duplicate Post

From the creators of the famous SEO tools, Yoast Duplicate Post is a free, easy-to-use plugin that adds a useful ‘Clone’ option to posts and pages in the WordPress admin panel Posts and Pages screens, respectively:

Clicking on the ‘Clone’ button creates an identical copy of the post or page, including the title. Moreover, with Yoast Duplicate Post, you can select multiple posts and pages to clone in bulk.
Read More About Yoast Duplicate Post
Duplicate Page

Next, we have Duplicate Page, a popular freemium plugin that makes it easy to duplicate posts and pages in WordPress, either individually or in bulk.
Duplicate Page works similarly to the Yoast Duplicate Post plugin, adding a ‘Duplicate This’ option to each item in the posts or pages sections of the WordPress admin panel. Therefore, cloning a post or page is simply a matter of choosing the one you wish to copy, hitting ‘Duplicate This,’ et voila, the plugin creates an identical clone with the status set to draft.
The Pro version of Duplicate Page costs just $15, which is a one-time payment for one website. It adds several additional features, such as the ability to assign user roles to duplicated pages, post prefixes and suffixes, and more.
WooCommerce users should note that the ‘Duplicate This’ option will not appear against products, as the integral WooCommerce ‘Duplicate’ option overrides it. More on that later in this article.
Read More About Duplicate Page
Copy Delete Posts

Not only does Copy Delete Posts allow you to clone posts and pages, but it also helps you bulk delete them.
Once the plugin is installed, a new ‘Copy & Delete Post’ item appears in the WordPress admin panel menu. You can configure the plugin from there with options like which elements should be copied, which duplicates should be deleted, etc.
Copying posts and pages with this plugin is super easy, thanks to the new ‘Copy’ option added to each page and post in the admin panel.
The free version of the plugin would suffice for most people. However, a premium version is also available starting from $19.98 that adds multisite features, copying of information from third-party plugins, configuration export and import, and more.
Read More About Copy Delete Posts
WP Post Page Clone
WP Post Page Clone works similarly to the other plugins we have listed, adding a ‘Click To Clone’ option to the posts and pages listed in the WordPress admin area. The plugin preserves all titles, content, and settings when cloning posts and pages. Moreover, it offers full cross-browser support, and it’s completely free.
Read More About WP Post Page Clone
Master Addons

Master Addons is not a dedicated plugin just for duplicating posts and pages in WordPress. Instead, it is a whole arsenal of tools to expand the capabilities of the famous page builder, Elementor, and one of those tools is a post/page duplicator for any post type.
Of course, as we already discussed, it is possible to clone pages in Elementor by saving them as templates. However, the post/page duplicator extension included with Master Addons reduces the cloning process to a single click. It works with any post type, and all third-party plugins are supported, including WooCommerce.
The free version of Master Addons includes the post/page duplicator extension, plus a heaps of other helpful Elementor tools. A Pro version costing from $39 per year adds even more. To see what features each version includes, click here.
Duplicating WooCommerce Products
If you just want to duplicate WooCommerce products rather than posts or pages, you’ll be happy to know that it is easy and requires no plugins. This is because WooCommerce already has a product duplication feature built in.
So, to duplicate a product, simply go to the main WooCommerce products screen, hover over the one you wish to clone, and click on ‘Duplicate’ from the options that appear:

The duplicate is then created, and you are taken directly to its edit screen. Once you have made any desired changes, you can simply go ahead and publish it. However, you will probably also need to edit the slug of the new product, as it will be identical to the source product’s slug, albeit with ‘-copy’ at the end.
A Word of Caution on Duplicating Pages and Posts in WordPress
When duplicating pages and posts in WordPress, remember that Google frowns upon content copied verbatim, seeing it as plagiarism and de-ranking sites that do it.
Therefore, it is advisable to amend your duplicated content to ensure that it is not identical to the source content.
Some Final Thoughts
It is relatively straightforward to duplicate posts and pages in WordPress. If you only need to do it occasionally, depending on which editor you use, then Method 1 or 2 above would suffice. However, if you do it often, one of our suggested plugins will make your life easier.
Before we go, we want to mention the importance of good hosting for your WordPress site. While plenty of cheap, shared hosting plans are available, they have limitations. For example, problems caused by other websites housed on the same server can negatively impact yours.
The high-performance WordPress virtual private server (or VPS) hosting from WP Bolt is a much better solution. With it, you get your own dedicated server space and resources, substantially reducing the possibility of interference from neighboring sites hogging resources or causing technical and security issues.
Best of all, with plans starting from just $15 per month or up to twenty domains, WP Bolt’s VPS hosting solutions are inexpensive, given the significant benefits they offer over shared hosting. To learn more about the different hosting types, please see our article ‘Shared Hosting vs. WordPress Hosting: Which Should You Choose?’
I’m a former construction industry professional who came out of the writer’s closet and am now totally comfortable with my creative side. My pronouns are smart, creative, witty, and dependable. I have written content in a number of niches including WordPress, plus I’m a blogger and affiliate marketer. If you’d like to know more about how I can help you, please head over to my website.
Want to speed up your web site?
WP Bolt makes it easy and affordable to have a High Performance WordPress VPS server.